question Qu | research R | negative Ne | claim C |
Would debates over theories be more productive if a platform identified consensus on the accuracy of the core facts, or elements, upon which they’re based?
This white paper is available as a Google Doc. Quernec has a Mastodon fork on Github with a discussion forum.
Research papers often involve complex and subjective theories subject to debate. However, they are built upon discrete elements—short, concise, demonstrably true or false assertions. Researchers debate the theories themselves, as well as these elements, on micro-blogging platforms like X and Mastodon. Currently, there is no way to isolate posts and threads debating these elements or determine if consensus has been established. As a result, research papers can pass peer review and become published without addressing accusations that they are based on premises generally considered demonstrably false. Conversely, researchers can struggle to get highly controversial theories published because there is no easy way to show that they are built on a foundation of solid, uncontroversial, and verified facts.
Mastodon functionally appears much like X, but it is open-source and decentralized, meaning each server can implement customizations to suit a particular niche, in this case researchers. Qurnec.org is a proposed customization that allows researchers to sign up with their ORCID ID and adds three features when composing a post to address these issues:
question Qu | In lieu of speculation, ask questions. Replies contain answers. |
research R | When further information is needed it will be a request for research, replies contain research protocols or data if it exists. |
negative Ne | Assertions that evidence does not exist are a negative, allowing replies to verify or challenge. |
claim C | Claims are demonstrably true or false based on the citations, allowing replies to verify or challenge. |
Two research papers, The Proximal Origin of SARS-CoV-2 and The Huanan Market Was the Epicenter of SARS-CoV-2 Emergence, divided the scientific community into camps: those who concurred with the authors' "natural origin" argument versus those who favored a "lab leak" theory. Both camps took to Twitter, arguing their cases in countless tweets. These tweets generally had short shelf lives and, being unstructured, did little to establish whether consensus had been reached on even the most basic core elements. There was no differentiation between posts from anonymous sources and those from respected researchers. For example, one of the papers claimed:
These analyses provide dispositive evidence for the emergence of SARS-CoV-2 via the live wildlife trade and identify the Huanan market as the unambiguous epicenter of the COVID-19 pandemic.
Following the preprint, critics posted tweets along the lines of:
The early case list was provided by the same Chinese authorities accused of covering up the lab leak. They may have excluded reported cases among Wuhan lab workers that predate the emergence in the wet market.
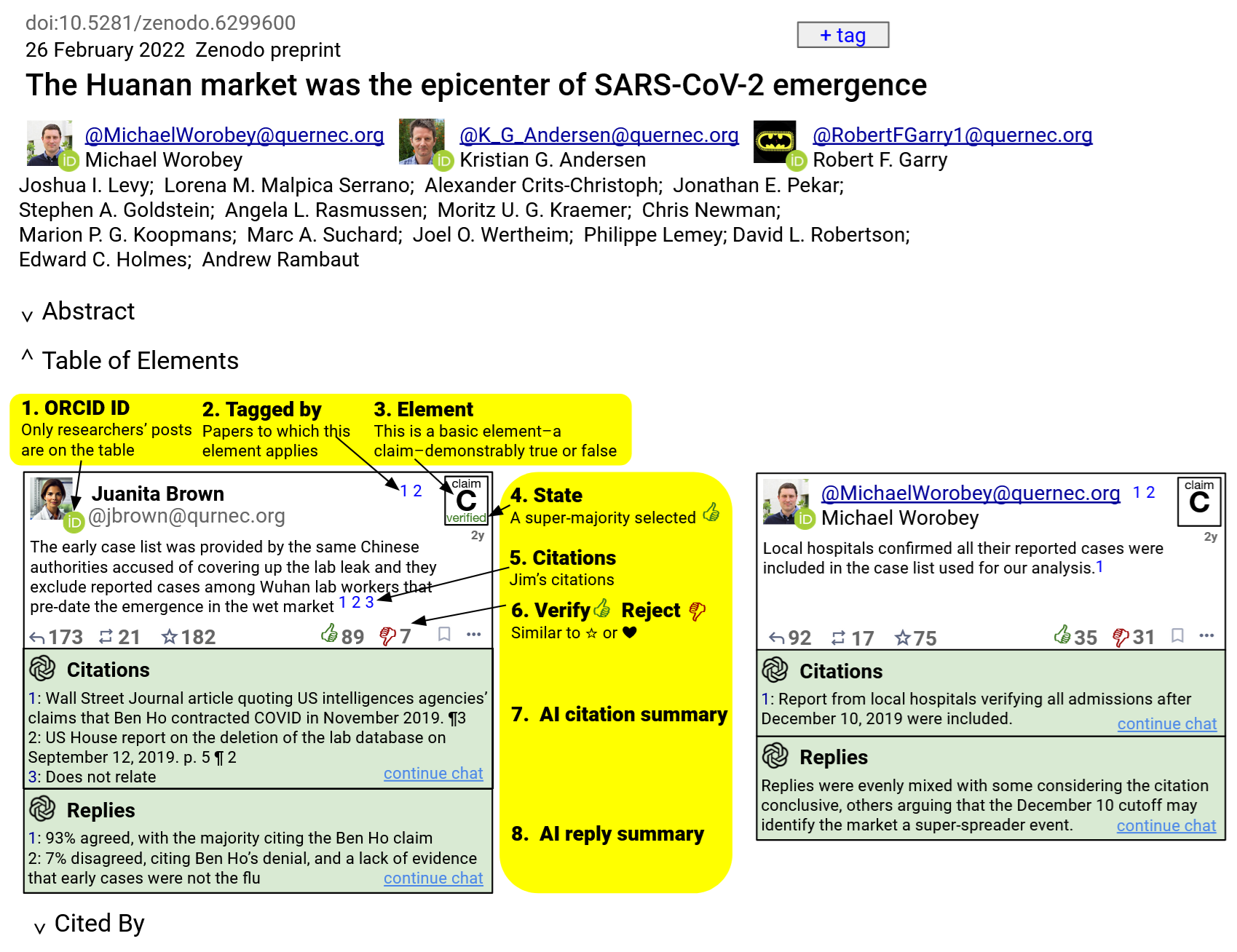
That criticism is an element, as it is a simple statement of fact for which consensus should be achievable. In addition to posting opinions on complex theories and subjective interpretations, it would have been helpful to structure such tweets to result in a Table of the Elements that displayed consensus on such basic statements of fact.
Qurnec proposes adding the following 3 items in yellow to structure posts:
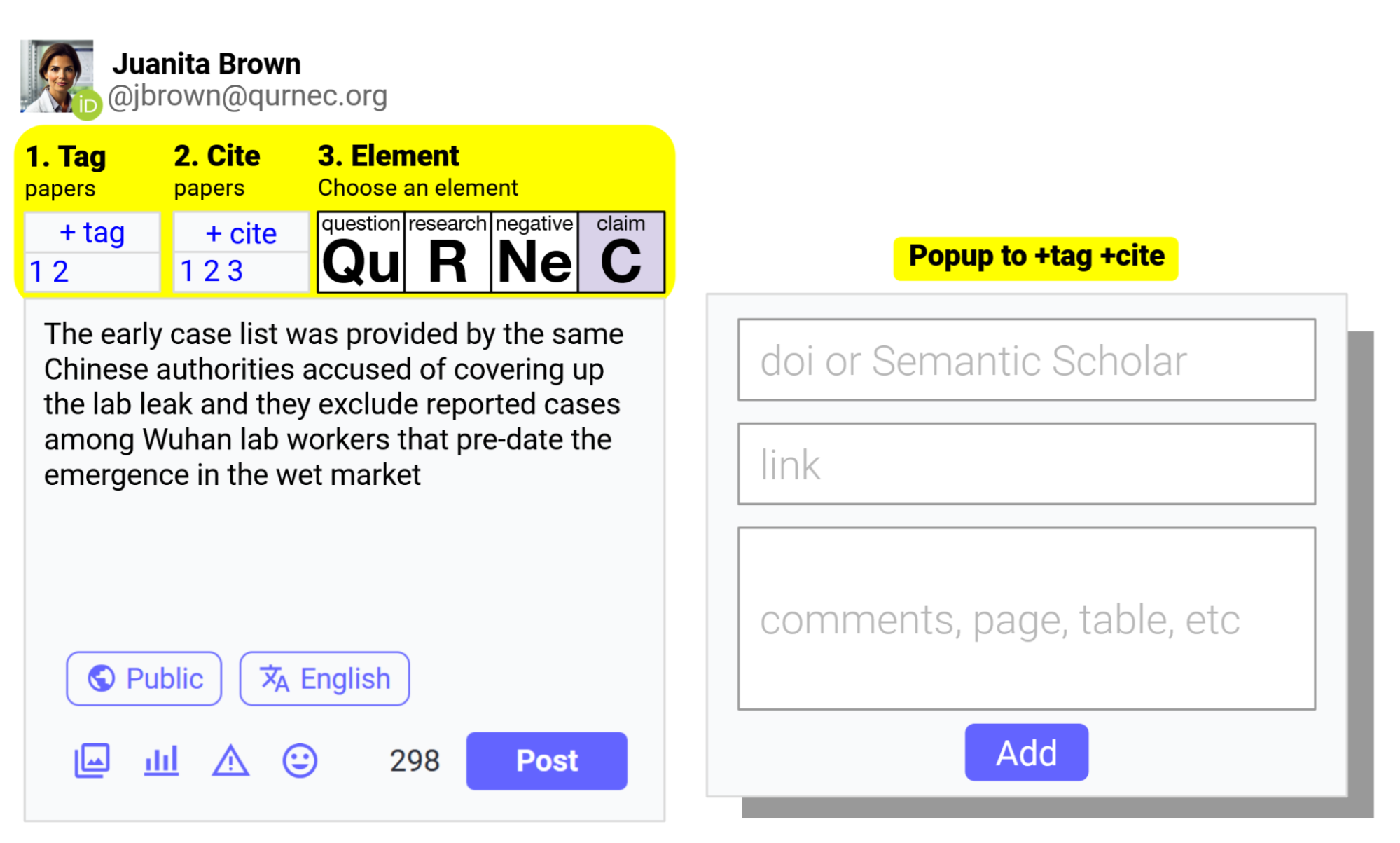
"Juanita" is an accredited researcher, and clicking the ORCID ID in her profile picture will display her body of research. Her post tags the two COVID origin papers by clicking +tag and providing the DOI or link. She does the same to cite the three papers she believes substantiate her post. She selects Claim to differentiate her post as a core element of the tagged papers for which she seeks consensus. With that structure, not only does Juanita’s post appear in her followers' timelines, but so do the two research papers she tagged, which bring up a dashboard with the elementary posts for the paper, such as this hypothetical example:
The yellow portions are explanatory mockups showing how “Juanita’s” post would appear in timelines and on dashboards. Users could reply as normal, either on the timeline or on this dashboard, but, since Juanita marked this post as an Element, her fellow researchers now have 🖒 and 🖓 in addition to the usual ☆ or ❤ to indicate ‘agree’ or ‘disagree’. By grouping all Elements that tag a paper on a single dashboard, researchers can, with a single-click, indicate if they agree or disagree with each, and reply to the ones where they’d like to explain. Selecting the counters next to 🖒 and 🖓 filters just replies from users who agreed or disagreed, and AI provides a concise summary of the points made by those who agreed and those who disagreed. The continue chat link loads a ChatGPT session with the cited papers and posts pre-loaded to quickly query.
Structuring posts would not require more time or effort. But, if it resulted in a Table of Elements for the preprint that looked like that example with a clear consensus that Juanita’s concern, on the left, is shared, perhaps the journals would have asked the authors to address their critics before publishing, as simulated on the right. In this simulation, no clear consensus was reached on its merit, so the peer reviewers could request the final paper include the new citation documenting local hospital’ findings, with a disclaimer about the opposing interpretations.
Researchers generally have an ORCID ID, as most journals require it to publish. ORCID ID supports an OATH single-sign like ‘Sign-in with Google’. Qurnec.org recommends using an ORCID ID to sign up, to tie posts/profiles to research works. The links to the user’s research on Semantic Scholar. This also helps prevent spam as users can select an option to filter out posts coming from non-ORCID users, and encourage productive, appropriate posts on Qurnec.org, as they tie to a body of research.
The Posts table needs to be expanded to add ‘Elements’, such as these:
question Qu answered | Anything speculative can be asked as a neutral question. Replies can add the element answer if the poster proposes this answers the question, and if a super-majority 🖒 an answer, the state of the question becomes answered |
research R completed | The poster explains in a simple post what research is needed. Replies can add the element results, the state of the research becomes completed |
negative Ne verified refuted | A claim that evidence does not exist, such as “No researcher has found…” If a clear majority reply with 🖒 the the state becomes verified (i.e. they cannot find the evidence either), or rejected. |
claim C verified refuted | A claim that something is demonstrably true. If a super-majority 🖒 or d the state becomes verified or rejected. |
When posting a reply to a Question, there exists the option to add 1 element:
answer A verified refuted | If the post asserts it answers the question, it adds the element answer, and if a super-majority 🖒 the answer, the state of the answer becomes verified and the state of the parent question becomes answered. The verified answers appear at the top of replies. |
When posting a reply to a Research, there exists the option to add 1 element:
data D verified refuted | If the post asserts it is citing research data that satisfies the Research request, it adds the element data, and if a super-majority 🖒 the data, the state of the data becomes verified and the state of the parent research becomes completed. The data appears at the top of replies. |
This also future-proofs research. The consensus may have been overwhelming when the research was published. But, perhaps later some of the claims are refuted with new evidence, and this page shows the current view.
This is a working paper to establish consensus on the usefulness of this approach and get feedback before doing the development work.
Is it worth the time to sign up for another social network? Researchers already spend a great deal of time debating issues on social networks, but if it’s in an unstructured format, it can be seen as a waste, as there’s no clear output. Posts have a lifespan of a few minutes, after which, few will notice them, and there’s no record of what consensus was reached.
Qurnec will be open source and public domain, so the algorithm can be refined to ensure the State properly reflects consensus, allowing for retroactively recalculating the State if needed. Many researchers are already on Mastodon, but for those on X the learning curve is minimal. As a community-driven product, Qurnec would continue to improve and add integrations with other research platforms like ResearchGate and SemanticScholar, to serve researchers.